import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from math import sqrt
from scipy import stats
np.random.seed(123)
from pydataset import data
from env import host, user, password
from wrangle_telco import wrangle_telco
from explore import correlation_exploration
Hypothesis Testing¶
What is Hypothesis Testing?

- Hypothesis tests are used to draw conclusions, answer questions, or interpret beliefs we have about a population using sample data.
- A hypothesis test evaluates two mutually exclusive statements about a population and informs us which statement is best supported by our sample data.
$H_0$: There is no difference between smokers' tips and the overall population's tip average.
$H_a$: There is a difference between smokers' tips and the overall population's tip average.
- After running and interpreting the values returned by the appropriate statistical test for my data, I will either fail to reject or reject the Null Hypothesis.
Here is a simple, yet detailed explanation of this process if you need a little more.
So What?
"There are two possible outcomes; if the result confirms the hypothesis, then you've made a measurement. If the result is contrary to the hypothesis, then you've made a discovery." - Enrico Fermi
Now What?

Important Terms¶
- a confidence level is the probability that if a poll/test/survey were repeated over and over again, the results obtained would be the same. It conveys how confident we are in our results. Raising your confidence level lowers your chances of Type I Errors, or False Positives. (Common examples might be 90%, 95%, or 99%)
- alpha --> $a$ = 1 - confidence level. If the resulting p-value from the hypothesis test is less than the $a$, which you set before you begin the test, then the test findings are significant. If it is close, it is at your discretion. The results still may be significant even though slightly above your chosen cutoff. Also, alpha is the maximum probability that you have a Type I Error.
For a 95% confidence level, the value of alpha is .05 which means there is a 5% chance that you will make a Type I Error (False Positive) or reject a True Null hypothesis.
- t-statistic is simply the calculated difference represented in units of standard error. The greater the magnitude of t, the greater the evidence against the null hypothesis. Why does it matter? Short Answer: It allows us to calculate our p-value!
- p-values are values we obtain from hypothesis testing. They represent the probability that our obtained result is due to chance given that our stated hypothesis is true.
- Looking for more information? I found this article useful.
Hypothesis Testing Errors¶

What is a Type I Error?
- A Type I Error is a False Positive, which I can think of as sounding a false alarm.
- I predict there is a difference or a relationship when in reality there is no difference or no relationship.
- I reject the Null hypothesis when the Null hypothesis is actually True.
So What?
- If I am trying to determine whether a customer will churn, and my model predicts that they will churn (positive for churn), but they do not end up churning (we made a False prediction), this is a False Positive. I may have wasted time and money trying to woo a customer who was not going to leave anyway.
What is a Type II Error?
- A Type II Error is a False Negative, which I can think of as a miss; I missed identifying a real difference or relationship that exists in reality.
- I predict that there is no difference or relationship when in reality there is a difference or relationship.
- I fail to reject the Null hypothesis when the Null hypothesis is actually false.
So What?
- If I am trying to determine whether a customer will churn, and my model predicts that they will not churn (negative for churn), but they end up churning (we made a False Prediction), this is a False Negative. I may have lost the opportunity to woo a customer that was going to leave, before they left.
Now What?
- In practice, if I create a classification model to predict customer churn, I can decide how to balance Type I and Type II Errors to have a model that suits my needs. In the instance of churn, which type of error would be more costly to the Telco company: a Type I Error or a Type II Error? Which would be more costly if I was trying to determine if a shadow in an x-ray were cancer?
T-Test - Continuous v Categorical Variables¶
What is a T-Test?
- A type of inferential statistic used to determine if there is a significant difference between the means of two groups which may be related in certain features.
- It compares a categorical and a continuous variable by comparing the mean of the continuous variable by subgroups or the mean of a subgroup to the mean of the population.
So What?
One Sample T-test is when I compare the mean for a subgroup to the population mean.
Are sales for group A higher when we run a promotion?
Two Sample T-test is when we compare the mean of one subgroup to the mean of another subgroup.
Now What?
# Set confidence level.
confidence_level = .95
# Set alpha.
alpha = 1 - confidence_level
- If the p-value is higher than your alpha, I fail to reject the Null Hypothesis.
- If the p-value is lower than the alpha, I reject the Null Hypothesis.
Types of T-Tests¶
A one-sample t-test compares the mean of a subgroup with the population mean.
subpop = array, list, Series
popmean = single value
t, p = scipy.stats.ttest_1samp(subpop, popmean)
A two-sample t-test compares the means of two subgroups.
subpop_a = array, list, or Series
subpop_b = array, list, or Series
t, p = scipy.stats.ttest_ind(subpop_a, subpop_b)
A one-tailed test looks for a specific difference: appropriate if I only want to determine if there is a difference between groups in a specific direction, positive only or negative only.
# Check one-tailed test for significance in positive direction. (greater than)
(p/2) < alpha
# Check one-tailed test for significance in negative direction. (less than)
(p/2) < alpha

A two-tailed test looks for any difference: appropriate if I want to test for significance without concern for a positive or negative direction.
# Check a two-tailed test for significance, non-directional.
p < alpha

One-Sample Example¶
# Create DataFrame from pydataset 'tips' dataset.
df = data('tips')
df.head()
# T-tests assume that the continous variable is normally distributed; quick check of this.
sns.distplot(df.tip)
plt.title('Distribution of Tips - Slight Right Skew')
plt.show()
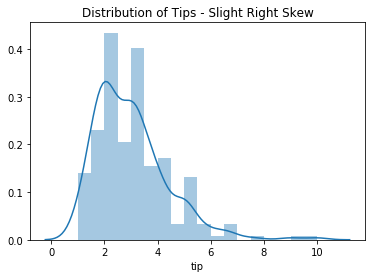
Mean and Median¶
- The distribution is slightly right-skewed, so I'll do a quick comparison of the mean and median of
df.tip.
- I can see below that the mean is slightly higher than the median. It's close enough to proceed, though.
print(f'The mean is: {df.tip.mean()}, and the median is {df.tip.median()}')
print('This is close enough to normal to continue.')
Create Hypotheses¶
$H_0$: There is no difference between smokers' tips and the overall population's tip average.
$H_a$: There is a difference between smokers' tips and the overall population's tip average.
Set Alpha¶
# Set Confidence Interval and Alpha; check alpha.
confidence_interval = .95
alpha = round(1 - confidence_interval, 2)
print(f'alpha = {alpha}')
Calculate p-value & t-statistic¶
- Based on the calculated p-value and t-statistic, I fail to reject my Null Hypothesis that there is no significant difference in the average tip of smokers and the overall population.
# Create smokers subset of our df.
smokers = df[df.smoker == 'Yes']
# Assign the mean of all tips to the variable pop_mean.
pop_mean = df.tip.mean()
# Pass in the tip column from smokers subset and mean of tip column from entire df.
t, p = stats.ttest_1samp(smokers.tip, pop_mean)
print(f't = {t:.3f}')
print(f'p = {p:.3f}')
print(f'Our p-value is less than our alpha: {p < alpha}')
Two Sample Example¶
# T-tests assume that the continous variable is normally distributed; quick check of this.
sns.distplot(df.tip)
plt.title('Distribution of Tips - Slight Right Skew')
plt.show()
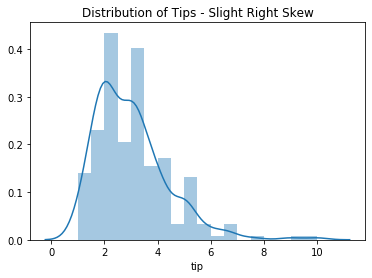
Mean and Median¶
- The distribution is right-skewed, so we see below the mean is slightly higher than the median.
- So, let's do a quick comparison of the mean and median of
df.tip.
print(f'The mean is: {df.tip.mean()}, and the median is {df.tip.median()}')
print('This is close enough to normal to continue.')
Create Hypotheses¶
$H_0$: There is no difference between women's and men's tips.
$H_a$: There is a difference between women's and men's tips.
Set Alpha¶
# Set Confidence Interval and Alpha; check alpha.
confidence_interval = .95
alpha = round(1 - confidence_interval, 2)
print(f'alpha = {alpha}')
# Create subsets of males and females from our original df.
males = df[df.sex == 'Male']
females = df[df.sex == 'Female']
Calculate p-value & t-statistic¶
- Based on the calculated p-value and t-statistic, I fail to reject my Null Hypothesis that there is no significant difference in the average tip of men and women.
t, p = stats.ttest_ind(males.tip, females.tip)
print(f'The t-statistic for the two sample t-test comparing male to female tips is {round(t,3)}.')
print(f'Our p-value is {round(p, 3)}.')
print(f'This means there is about a {round(p * 100, 2)}% chance that we observe the data we have.')
print(f'Our p-value is less than our alpha: {p < alpha}')
Correlation - Continuous v Continuous Variables¶
What is a correlation test?
- Correlation is a statistical measure that describes how two continuous variables are related and indicates that as one variable changes in value, the other variable tends to change in a specific direction.
Positive Correlation: both variables change in the same direction.
Neutral or No Correlation: No relationship in the change of the variables.
Negative Correlation: variables change in opposite directions.

So What?
- The Pearson correlation coefficient, r, is a unitless, continuous numerical measure between -1 and 1, where 1 = perfect positive correlation and -1 = perfect negative correlation. It can be used to summarize the strength of the linear relationship between two data samples.
- The bigger the value of a correlation coefficient, the less likely it is to have occurred merely by chance, and the more likely it is that it has occurred because it represents a genuine relationship between the two variables in question.
- Some machine learning algorithms, such as Linear Regressions, may not perform as well when there is multicolinearity or independent variables that are correlated.
Now What?
- Calculate the Pearson correlation coefficient, r.
- Calculate the coresponding t-values.
- Test whether the t-values are significant or not, p-value.
We can use
r, p = stats.pearsonr(x,y)to find r and p-values.
Keep in mind that...
- Correlation doesn't mean that one variable is causing the change in another variable!
- Pearson's correlation tests measure the linear relationship between 2 variables and not other types of relationships. (There are other correlation tests, like Spearman's correlation, that test for non-linear relationships.)
- Correlations can be misleading when confounding variables are ignored. There may be a third variable influencing the other two variables in your correlation test. (An increase in ice cream sales causes an increase in murder rate.)
Pearson's r Examples¶
My Correlation Function¶
Here you can see the guts of my function correlation_exploration that I created and imported to make this processes faster. I got tired of writing the same code over and over.
def correlation_exploration(df, x_string, y_string):
'''
This nifty function takes in a df, a string for x variable,
and a string for y variable and displays their correlation.
'''
r, p = stats.pearsonr(df[x_string], df[y_string])
df.plot.scatter(x_string, y_string)
plt.title(f"{x_string}'s Relationship with {y_string}")
print(f'The p-value is: {p}. There is {round(p,3)}% chance that we see these results by chance.')
print(f'r = {round(r, 2)}')
plt.show()
My Wrangle Function¶
Here you can see the guts of my function to get my Telco data from the Codeup database and clean it up for use in some examples.
def wrangle_telco():
"""
Queries the telco_churn database
Returns a clean df with six columns:
customer_id(object), monthly_charges(float),
tenure(int), total_charges(float),
phone_service(object), internet_service_type_id(int)
"""
df = get_data_from_sql()
df.tenure.replace(0, 1, inplace=True)
df.total_charges.replace(' ', df.monthly_charges, inplace=True)
df.total_charges = df.total_charges.astype(float)
return df
telco = wrangle_telco()
telco.info()
telco.head()
Create Hypotheses¶
- Does tenure correlate with monthly charges?
$H_0$: There is no linear correlation between tenure and monthly charges.
$H_a$: There is a linear correlation between tenure and monthly charges.
Set Alpha for All Correlation Tests¶
# Set Confidence Interval and Alpha; check alpha.
confidence_interval = .95
alpha = round(1 - confidence_interval, 2)
print(f'alpha = {alpha}')
Calculate p-value & t-statistic¶
- Based on my calculated r and p-value, I reject the Null hypothesis. The r value informs us that there is a small positive linear correlation between tenure and monthly charges, and our p-value informs us that the finding is significant.
- We can see from the low r value that the correlation, though significant, is not strong.
correlation_exploration(telco, 'tenure', 'monthly_charges')
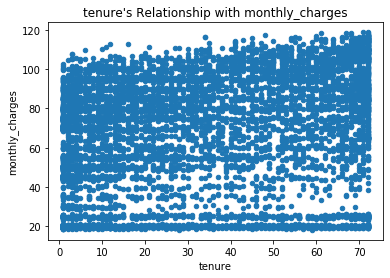
Create Hypotheses¶
- Does tenure correlate with total charges?
$H_0$: There is no linear correlation between tenure and total charges.
$H_a$: There is a linear correlation between tenure and total charges.
Calculate p-value & t-statistic¶
- Based on the r and p-value, I reject the Null hypothesis. There is a strong correlation, r = 0.83, between tenure and total charges.
- This is not surprising because total charges necessarily add up the longer a customer remain with the company, tenure. Our p-value of 0 informs us that the finding is significant.
correlation_exploration(telco, 'tenure', 'total_charges')
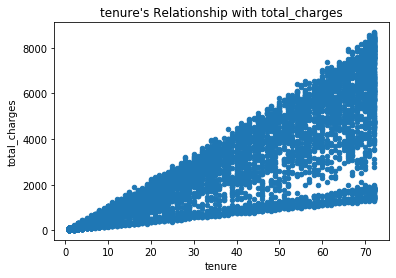
Create Hypotheses¶
- What happens if I control for phone and internet service?
$H_0$: There is no linear correlation between tenure and monthly charges for customers who don't have phone but do have DSL services.
$H_a$: There is a linear correlation between tenure and monthly charges for customers who don't have phone but do have DSL services.
# Create a subset of customers without phone service but with internet.
# This ONLY includes DSL as I found that Fiber customers ALL have phone service.
no_phone_yes_dsl = telco[(telco.phone_service == 'No') & ((telco.internet_service_type_id == 1) | (telco.internet_service_type_id == 2))]
no_phone_yes_dsl.head()
Calculate p-value & t-statistic¶
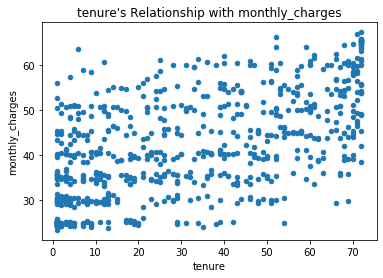
- I reject the Null hypothesis that there is no correlation between tenure and monthly charges for customers who don't have phone but do have DSL based on the calculated p-value being below our alpha of 0.05 and our r of 0.59.
# The relationship between tenure and monthly charges for customers that don't have phone service
# but DO have DSL
correlation_exploration(no_phone_yes_dsl, 'tenure', 'monthly_charges')
Create Hypotheses¶
$H_0$: There is no linear correlation between tenure and monthly charges for customers with phone and Fiber services.
$H_a$: There is a linear correlation between tenure and monthly charges for customers with phone and Fiber services.
# Create subset of customers who have Fiber... all Fiber customers also have phone service
yes_phone_yes_fiber = telco[telco.internet_service_type_id == 2]
yes_phone_yes_fiber.head()
Calculate p-value & t-statistic¶
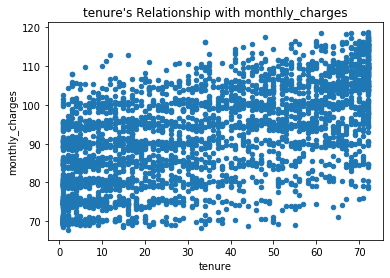
- I reject the Null hypothesis that there is no correlation between tenure and montlhy charges for customers who have Fiber and phone services based on the p-value being below our alpha of 0.05 and our r of 0.62.
- There is a positive correlation between tenure and monthly charges for customers with Fiber and phone service.
# the correlation of tenure and monthly charges for customers who have phone and Fiber service
correlation_exploration(yes_phone_yes_fiber, 'tenure', 'monthly_charges')
Chi Square ($x^2$) - Categorical v Categorical Variables¶
What is a Chi Square test?
- The Chi Square test is used to determine whether there is a statistically significant difference between the expected and observed frequencies in one or more categories. Observations are classfied into mutually exclusive classes. In other words, it is a way of testing for group membership.
So What?
- The chi square test works by comparing the observed/actual contingency table against the expected/predicted contingency table that would be the case if group membership in the variables were independent.
Were people with a higher ticket class on the Titanic more likely to survive?
$H_0$ = Survival rate is independent of ticket class.
$H_a$ = Survival rate is not independent of ticket class.
Does the type of service package a customer has affect the likelihood that she will churn?
$H_0$ = Churn is independent of type of service package.
$H_a$ = Churn is not independent of type of service package.
Now What?
# ctab == observed values
ctab = pd.crosstab(df.Series, df.Series)
#expected == values we would expect to see if the variables are independent of each other.
chi2, p, degf, expected = stats.chi2_contingency(ctab)
Chi Square Examples¶
Steps
- Aquire data
- Create Hypothesis - Null Hypothesis: The two variables are independent.
- Set your confidence level and alpha
- Calculate Test Statistic - run chi square test and use p-value to decide whether to reject the Null Hypothesis that the variables or categories are independent.
# Create 'tips' df using pydataset.
tips = data('tips')
tips.head()
Create Hypotheses¶
$H_0$ = Whether a person is a smoker is independent of his/her sex.
$H_a$ = Whether a person is a smoker is not independent of his/her sex.
Set Alpha¶
confidence_level = .95
alpha = round(1 - confidence_level,2)
alpha
Calculate p-value¶
- I fail to reject the Null hypothesis that whether a person is a smoker is independent of his/her sex based on the p-value being above our alpha.
- Our $x^2$ test informs me that the two categories, smoker and sex, are independent.
# Create the crosstab.
ctab = pd.crosstab(tips.smoker, tips.sex)
ctab
Chi2, p, degf, expected = stats.chi2_contingency(ctab)
print(f'Our p-value is {p}.')
print(f'Our p-value is less than our alpha: {p < alpha}')
Create Hypotheses¶
$H_0$ = Whether a person churns is independent of the package type they purchase.
$H_a$ = Whether a person churns is not independent of the package type they purchase.
Create a df from values and labels.¶
- I can create a visual to go with this.
index = ['Churn', 'No Churn']
columns = ['Product A', 'Product B']
observed = pd.DataFrame([[100, 50], [120, 28]], index=index, columns=columns)
observed
Calculate p-value¶
- I reject the Null hypothesis that whether a person churns is independent of the package type they purchase based on the p-value being below the set alpha.
- My $x^2$ test informs me that the two categories, package and churn, are not independent.
Chi2, p, degf, expected = stats.chi2_contingency(observed)
print(f'Our p-value is {p}.')
print(f'Our p-value is less than our alpha: {p < alpha}')