
What Makes Python So Great?
According to w3schools.com
- Python was designed for readability, and has some similarities to the English language with influence from mathematics.
- Python uses new lines to complete a command, as opposed to other programming languages which often use semicolons or parentheses.
- Python relies on indentation, using whitespace, to define scope; such as the scope of loops, functions and classes. Other programming languages often use curly-brackets for this purpose.
- Python has syntax that allows developers to write programs with fewer lines than some other programming languages.
- Python runs on an interpreter system, meaning that code can be executed as soon as it is written. This means that prototyping can be very quick.
So What?
- Python can be treated in a procedural way, an object-oriented way or a functional way.
- Python can connect to database systems. It can also read and modify files.
- Python can be used to handle big data and perform complex mathematics.
Python also has libraries that are invaluable in the field of Data Science such as:
Now What?
Click here for a great Python cheatsheet that covers pretty much any basic thing you might want to know.
You might want to check and see what version of Python you are running by typing the following in your terminal:
python --version
You can also run the following right in your Jupyter Notebook:
!python --version
len() and type() functions¶
len(sequence_object)
type(object)
I want to introduce two python functions nice and early because I will use them a lot! I can use the built-in function len() to return the number of elements in a sequence like a string or a list. I can use the built-in function type() to check my data type.
Data Types¶
Numeric Types -> int, float¶
An int is a whole number and a float is a decimal number. Both int and float data types are immutable objects. Jumping ahead a bit, you will find out that missing values are also considered float types.
type(7)
type(7.5)
import numpy as np
type(np.NaN)
Boolean Type -> bool¶
Boolean values, True and False, are not strings, so they do not go in quotation marks, and they are case sensitive. Rather they inform me if my expression or condition logic evaluates to True or False. It's common to hear that a value is truthy or falsy. You can also think of boolean values as binary integers in that True == 1 and False == 0. This data type is also immutable.
# The comparison returns `False`, a bool value because the lengths are not the same.
len('violet') == len('blue')
type(len('violet') == len('blue'))
False != True
True == 1
False == 0
Sequence Types -> str, list, tuple, range¶
A Python String can be surrounded by single or double quotation marks. I can have an empty string with no characters or a string can contain multiple words, numbers, symbols, and whitespace characters. The string data type is an immutable object, so if you want to keep changes you make to your string using a method, for example, you have to either assign or reassign the results of the operation to a variable. Click here to see what you can do with strings.
type('Python rocks!')
type("a")
type('')
A Python list can contain elements of different data types and is a mutable object. Duplicate values are allowed. Notice the square brackets surrounding the elements. Click here to see what you can do with lists.
I can create a Python list in several different ways:
# I can create an empty list as simply as this with the list constructor...
new_empty_list = []
print(type(new_empty_list))
new_empty_list
# I can create a populated list from the very start; notice it can contain various data types.
mixed_list = [1, 3.5, 'apple']
print(type(mixed_list))
mixed_list
A Python tuple is an ordered, immutable object. Duplicate values are allowed. Notice the parentheses surrounding the pair of elements.
type((1, 3))
type(('red', 'blue', 'green'))
A Python range() constructor creates a range object.
range(start, stop, step)
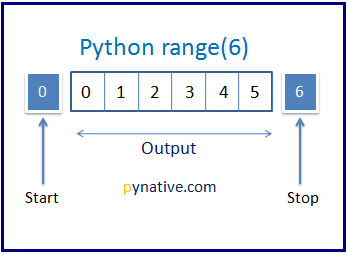
If I pass only one integer as my argument, the start (inclusive) is 0 and stop (exclusive) 1 less than my argument. The step defaults to 1 if not specified.
range(6)
I can loop through my range object like this... (more on loops later)
for i in range(6):
print(i)
I can also wrap my range object in the built-in list() constructor to return a list of the integers specified by my range object.
list(range(6))
Here, I specify that the range starts at 0 and stops at 10 (exclusive) moving in steps of 2 instead of 1.
r = range(0,10,2)
r
evens_list = list(r)
evens_list
Now I can pass this list to other functions like this...
# I can sum the integers in my list.
sum(evens_list)
# I can return the number of elements in my list.
len(evens_list)
Mapping Type -> dict¶
A Python dictionary object is an unordered collection of data values made up of key:value pairs with a : separating each key and its value and a , separating each key:pair. It is a mutable object but it does not allow duplicate keys. If you try to assign a new key:value pair to an existing dictionary with a key that already exists in your dictionary, it will not add the new key:value pair but instead update the value of the existing key in your dictionary. Notice the curly brackets surrounding the key:value pairs.
I can create a Python dictionary in several different ways:
# I can create an empty dictionary as simply as this with the dictionary constructor...
new_empty_dictionary = {}
print(type(new_empty_dictionary))
new_empty_dictionary
# I can create a populated dictionary from the very start; notice it can contain key/value pairs.
day_dict = {'weekday': 'Thursday', 'day': 20, 'month': 'October', 'year': 2020}
print(type(day_dict))
day_dict
# Watch what happens if I try to add a new key:value pair to my dictionary with a duplicate key.
day_dict['weekday'] = 'Saturday'
# When I use dictionary indexing to access the value of weekday now, the value of weekday has been updated.
day_dict
Dictionary indexing is a little different from other sequences like lists and tuples; I access values in a dictionary by passing the key into square brackets instead of an integer for the index location. I'll go into dictionary functionality more here.
day_dict['weekday']
day_dict['day']
Set Type -> set¶
A Python set object is an unordered and unindexed collection that is immutable and contains only unique values. Notice the curly brackets. I've opted to focus on list and dictionary methods in this basic notebook, but here is a link to set methods for future use. They are quite useful when looking for differences or similarities between elements in different sequences.
# Here I use curly brackets to create a set.
a_set = {1, 1, 2, 5}
type(a_set)
When I use the built-in len() function, I see that only the unique elements in the set are counted. This can come in very handy when checking for unique elements in a list.
# This tells me there are 3 unique elements in a_set.
len(a_set)
# Here I use square brackets to create a list containing the same elements as in my set.
a_list = [1, 1, 2, 5]
len(a_list)
# This list does not contain all unique elements.
len([1, 1, 2, 5]) == len({1, 1, 2, 5})
Operators¶
This is just a quick reference for Python operators. I'll be using these in action throughout this and in all future notebooks. Here is a link to all python operators in W3Schools that is fantastic.
Assignment Operators¶

Comparison Operators¶

Arithmetic Operators¶

Logic Operators¶

String Operations¶
String Methods¶
There are a ton of useful built-in methods that can be accessed using dot notation with Python string objects. These are basically built-in functions that can be used with this type of object. To check out some of these methods, let's create a variable that holds a string object as an example. To check out way more, check the doc here.
a_string = 'I am a string!'
type(a_string)
.lower(), .upper(), .capitalize(), .title(), swapcase()¶
These string methods return new strings with the characters either lowercase or uppercase in various ways. Since Python strings objects are immuntable, if I want to store the new string, I have to assign it to a new variable or reassign it to the original variable. Check out the examples below:
a_string.lower()
# Notice that the original string has not been mutated because I didn't reassign the results above.
a_string
a_string.upper()
a_string.capitalize()
a_string.title()
a_string.swapcase()
# Again, using a string method doesn't mutate my original string; it returns a copy I can use or assign.
a_string
.islower(), .isupper()¶
I can use these methods to return a bool value if all of the characters in my string are lowercase or uppercase.
# I can assign my string in all caps to a variable for further use.
caps = a_string.upper()
caps
# I can check my string for all upper- or all lowercase letters.
caps.isupper()
caps.islower()
.strip(), .replace()¶
These string methods are useful to perform a little string cleanup by removing any whitespace from the beginning or end of my string and replacing a string with another string.
# The default behavior for strip is to take out leading or trailing whitespace; `[chars]` is optional.
str.strip([chars])
str.lstrip([chars])
str.rstrip([chars])
# The default behavior of replace replaces ALL occurences of the old with the new; this can be adjusted.
string.replace(old, new, [count=-1])
a_string = ' I am a string. I am a messy string! '
# Strip whitespace from beginning and end of string.
a_string.strip()
# Strip whitespace from beginning of string.
a_string.lstrip()
# Strip whitespace from end of string.
a_string.rstrip()
b_string = '!?I have junk at the front I don\'t need.'
# The default is whitespace, but I can strip out other characters as well.
b_string.strip('!?')
a_string.replace('string', 'something')
# I can pass in a number of occurences to replace if I don't want to replace them all.
a_string.replace('string', 'something', 1)
# I can chain these methods together, too! I can replace and strip at the same time.
a_string.replace('string', 'something', 1).strip()
.isalnum(), .isalpha(), .isdigit(), .isspace()¶
These handy string methods return a bool value telling me if all of the characters in the string are either alphanumeric, alphabetic, digits, or tabs/spaces/newlines respectively.
# Define variables for use below
alpha = 'alphabetic'
alphanumeric = 'unit9'
digits = '210'
alpha.isalpha()
alphanumeric.isalnum()
digits.isdigit()
digits.isspace()
.split(), .partition(), .join()¶
I can split my string using a specific separator like a space or a hyphen and return the elements in a list (.split()) or tuple (.partition()), and I can join on a specific separator, too.
# I can split a string into a list; the default separator is a whitespace if none is passed. I can pass an integer along with a separator to control the number of splits, but this is also optional.
str.split(separator, maxsplit=int)
# I can split a string into a tuple containing three elements, 1-elements before value, 2-value, 3-elements after value.
str.partition(value)
# I can join all of the items in a sequence_of_strings (an iterable) and join them on the string_separator I specify.
'str_separator'.join(sequence_of_strings)
# Now I have a list of the elements in my string and can access them using indexing.
a_list = a_string.split()
a_list
a_list[-1]
a_list[0]
# I can use partition to break my string on the separator I pass as an argument and index into the tuple.
a_tuple = 'Codeup rocks!'.partition(' ')
a_tuple
# Now I can use indexing to access strings in my tuple.
a_tuple[0]
# I can join the elements of my list on a whitespace or some other separator, as well.
' '.join(a_list)
phone_string = '210-299-2080'
# I can split on a specific separator and even control how many times I split.
phone_string.split('-', maxsplit=1)
.startswith(), .endswith()¶
I can return a bool value indicating if a string starts or ends with a substring I pass as an argument.
# I have to pass a value, but specifying the index position at which to start and end my search is optional.
str.startswith(value, start, end)
# The same applies here.
str.endswith(value, start, end)
e_string = 'automobile'
e_string.startswith('auto')
.count()¶
I can count the number of occurences of a particular value in a string. The starting and ending index values are optional parameters that allow me more precision if I need it.
# I have to pass a value, but specifying the index position at which to start and end my search is optional.
str.count(value, start, end), where :
# There are two o characters in my e_string.
e_string.count('o')
String Formatting¶
The print() function will display your value to your screen. I can format my output in several ways, a few of which I will demonstrate below.
f-strings allow me to print a string AND varibales by passing an f-string to my print function with variables inside of curly braces. Here is more on f-strings if interested.
a_num = '20'
print(f'The number {a_num} contains {len(a_num)} digits!')
name = 'Codeup'
company = 'Career Accelerator'
print(f'{name} is a {company}.')
The .format() method is another way to combine strings and variables in a print statement.
cnt = 3
price = 1.99
total = cnt * price
print('I bought {} coffees at {} each for a total of {}.'.format(cnt, price, total))
The string modulo operator % offers a lot more string formatting options, but to keep this basic notebook basic, I'll just add a link to a very detailed look at options for when you hit a case that requires more than the above two options.
String Concatenation allows me to combine strings using the + operator. When a built-in operator or function displays different behaviors based on the type of object it is used with, this is called Operator Overloading.
greeting = 'Hi'
name = 'there!'
print(greeting + ' ' + name)
String Multiplication allows me to create a new string with the original string repeated n times by using the * operator. This is another example of Operator Overloading.
s = 'happy '
s * 5
s * 0
Comments in this section? Sure, why not?!
# You can use a hashtag to add comments to your code.
2 + 2
"""
You can use triple quotes, single or double,
to write multi-line comments or add docstrings
to functions, which we'll see in the next notebook.
"""
2 + 2
String Indexing & Slicing¶
Positive String Indexing
Python assigns a number to each character in a string, starting from 0 counting up to the last character in the string. We use these numbers to access specific characters in a string or elements in other sequences like lists or tuples.

Negative String Indexing
Python also allows us to reference characters in a string using negative indexing that assigns -1 to the last character in the string. Negative indexing is very useful when you don't know how many characters are in a string, but you want to grab the last one or two only. We will see this same indexing system when we dive into Python lists, too.
The Indexing Operator (square brackets) [] allow me to isolate a character in a string by passing in a number representing the index position of a specific character.
e_string
# I can grab the first character in a string.
e_string[0]
# I can grab the last character in a string.
e_string[-1]
String Slicing
I can slice a string using the same bracket notation as above; slicing allows me to isolate multiple characters in a string.
str[start (inclusive): stop (exclusive): step]
# I can leave out the start index if I want to start from 0.
e_string[:4]
# I can leave out the column index if I want to end at the end or -1.
e_string[4:]
# I can reverse my string by passing -1 as my step argument with default start and stop.
e_string[::-1]
Handy Keywords¶
in, not in¶
These are two very useful membership operators used to verify if a string contains a certain substring or character. These will be useful with other sequence types, as well.
# Define variables for use below.
vowels = 'aeiou'
o_string = 'o'
p_string = 'P'
# I can use the .lower() method on my string to catch any capital letters in my string.
o_string.lower() in vowels
p_string.lower() not in vowels
# Print out the string stored in my `b_string` variable.
print(b_string)
'junk' in b_string
List Operations¶
# I create my exmple list by surrounding a sequence of elements with square brackets.
color_list_original = ['red', 'yellow', 'violet', 'salmon']
# I can also use the `list()` constructor to create a list from another type of sequence.
clothes = ('shirt', 'pants', 'skirt', 'socks')
type(clothes)
clothes_list_original = list(clothes)
type(clothes_list_original)
I can use the .copy() method to create a copy of my sequence if I want to keep my original list intact because many of the list methods below perform in-place operations; this means they mutate my original list.
color_list = color_list_original.copy()
clothes_list = clothes_list_original.copy()
.append(), .extend()¶
I can add an item to the end of an existing list, and I can add a list to another list by joining them together respectively. These manipulations will mutate or change my original list.
list.append(element)
list.extend(iterable)
# I can add an item, shoes, to my clothes_list.
clothes_list.append('shoes')
# My original clothes_list now contains the appended item, shoes.
clothes_list
color_list2 = ['indigo', 'orange']
# I can add the items in color_list2 to my original color_list.
color_list.extend(color_list2)
color_list
# If I tried to use .append() to add my two lists together, this would happen...
clothes_list.append(color_list2)
# I get a nested list object. If you don't want this, use .extend().
clothes_list
# Redefine lists to use in examples.
color_list = color_list_original.copy()
clothes_list = clothes_list_original.copy()
# I can also add two lists using the + operator and assign my new list to a variable.
new_list = color_list + clothes_list
new_list
.insert(), .remove(), .pop()¶
I can add an item to a list at a given position, remove the first item from my list that matches my specified value, and remove an item at a specific position from my list and return the item respectively. These manipulations will mutate or change my original list.
# I can insert an element into an existing list at a specified index position.
list.insert(index_position, element)
# I can remove the first occurrence of an element in a list.
list.remove(element)
# I can remove an element at a specified index position from a list and return that element.
list.pop(index_position)
# Redefine lists to use in examples.
color_list = color_list_original.copy()
clothes_list = clothes_list_original.copy()
# I pass the index of the element before which I want to insert my new element, 'aqua'.
color_list.insert(0, 'aqua')
# Now aqua is the first element in my list. If I used .append(), it would be the last.
color_list
# I will remove the item 'yellow' from my color_list
color_list.remove('yellow')
color_list
# I will remove and return the second item in my list, index 1, `red`.
color_list.pop(1)
# Notice after I pop 'red', it is removed from my original list as well; it removes and returns the element.
color_list
.reverse(), .sort()¶
I can reverse the elements in my list or sort the elements alphabetically.
# I can perform a simple reverse of order on my original list.
list.reverse()
# I can sort my list in ascending/alphabetical order by default, passing no arguments to .sort(), or I can pass arguments for the reverse and key parameters to do way more complex sorts.
list.sort(reverse=True|False, key=function)
# Redefine lists to use in examples.
color_list = color_list_original.copy()
clothes_list = clothes_list_original.copy()
# I can reverse the elements in my original list.
color_list.reverse()
color_list
# I can sort the elements in my original list alphabetically by default.
clothes_list.sort()
clothes_list
# I can sort in reverse alphabetical order, too!
clothes_list.sort(reverse=True)
clothes_list
# I can pass a function, built-in or created, as a sorting key or criteria. Here I sort by string length!
color_list.sort(key=len)
color_list
List Indexing & Slicing¶
Once you understand positive and negative string indexing and slicing, you understand positive and negative list indexing. The difference is that the index number represents an element in your list (or tuple) instead of a character in your string. https://pynative.com/wp-content/uploads/2018/10/python_range.png
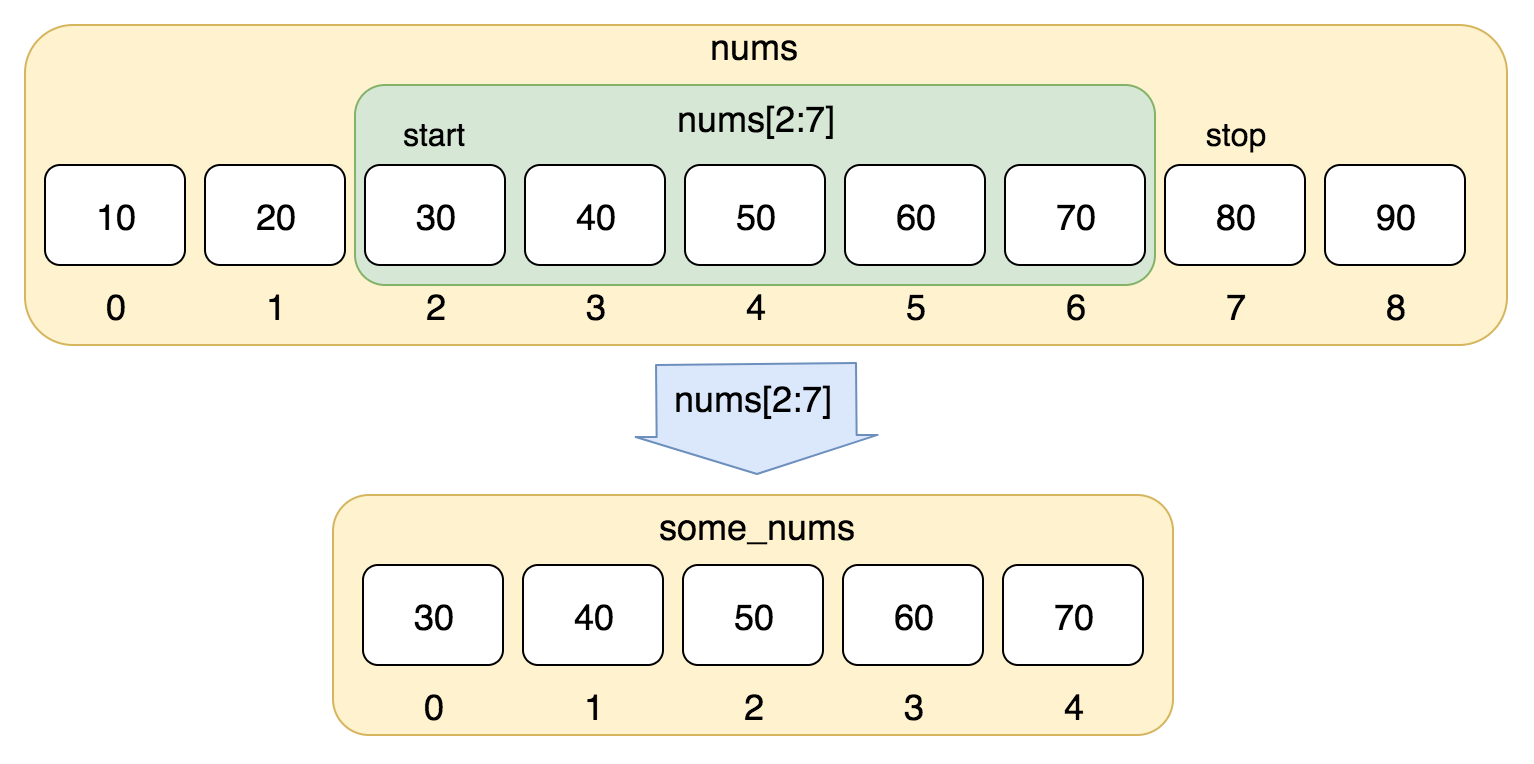
color_list = color_list_original.copy()
color_list
# The default start is 0 and stop is exclusive, just like slicing strings.
color_list[:4]
# I can use indexing to reverse my list by selecting all elements ([::]) and passing a step of -1.
color_list[::-1]
# I can access values in a nested list, too.
nested_list = ['this', 'is', 'the', 'outer', 'list', ['and', 'inner', 'one']]
nested_list
# The 5th element in my list is a list, and I can grab elements from that list using the second [].
nested_list[5][1]
Dictionary Operations¶

# Define my example dictionary
day_dict = {'weekday': 'Thursday', 'day': 8, 'month': 'April', 'year': 2021}
.keys(), .values(), .items()¶
I can return a list of keys, values, or items (key/value pairs) from my dictionary object.
day_dict.keys()
day_dict.values()
day_dict.items()
I can create a dictionary from two lists using an awesome function called zip(). This is just a preview of zip; we'll see more in zip and other cool python functions in a future notebook.
# Define the lists I want to be keys and values in my dictionary.
key_list = ['name', 'sign', 'age']
value_list = ['Freya', 'Aquarius', 1]
fam_dict = dict(zip(key_list, value_list))
fam_dict
Dictionary Indexing¶
I can access a value in my dictionary by passing the key into the indexing operator [].
fam_dict
fam_dict['name']
I can loop through my dictionary using the .keys(), .values(), and .items() methods. (More on loops in a future notebook.)
# Print each key in my dictionary.
for key in fam_dict.keys():
print(key)
# Print each value in my dictionary.
for value in fam_dict.values():
print(value)
# Print each item in my dictionary as a tuple.
for item in fam_dict.items():
print(item)
Mixed Sequence Structures¶
I can dig into more complicated structures using indexing, as well. I have to be sure I use the appropriate indexing for each sequence. I'll demonstrate below:
# Create a list of four dictionaries.
fam_list = [{'name': 'Milla', 'sign': 'Virgo', 'age': 15},
{'name': 'Freya', 'sign': 'Gemini', 'age': 1},
{'name': 'Starbuck', 'sign': 'Aries', 'age': 5},
{'name': 'Faith', 'sign': 'Aquarius', 'age': 100}]
fam_list
# Verifying the data type is a list.
print(type(fam_list))
Since this is a list, recall that I pass an integer representing an index position to the indexing operator like below. Revisit list indexing and slicing here.
list[0]
I can also slice my list to return segments of the sequence like this:
list[:2]
# This returns the first element in my list, which happens to be a dictionary.
fam_list[0]
# This slice returns the first two elements in my list, which happen to be dictionaries.
fam_list[:2]
What if I want to dig into the dictionaries in the list? I can do this by indexing into the list with the appropriate syntax and then the dictionary with the appropriate syntax.
Below I pass an iteger to the indexing operator to return the first element in my list. Since the first element in my list is a dictionary, I pass a key to the indexing operator to return the value that is paired with that key in the dictionary. Revisit dictionary indexing here.
# I return the first dictionary in my list and the value for the name key in my dictionary.
fam_list[0]['name']
# I can return the value for the name key for each dictionary in my list like this:
for element in fam_list:
print(element['name'])
I can return the name of the oldest person/animal in my dictionary. This code utilizes for loops and an if statement to find the dictionary with the highest value for age and then print values from that dictionary. This is one way to get the values I want, but as will often be the case, there are many ways to accomplish my goal. I'll revisit this goal in a future notebook and explore other ways of getting this information.
# I iterate through my list adding the age from each dictionary to a new list, `ages` that I define outside of my loop.
ages = []
for element in fam_list:
ages.append(element['age'])
# I use the max() function to return the max age in `ages` and assign that integer to `max_age`.
max_age = max(ages)
# I iterate through my list again and print different values if the age value matches `max_age`.
for element in fam_list:
if element['age'] == max_age:
print(f"The oldest person in the list is {element['name']}.")
print(f"Her sign is {element['sign']}.")
print(f"Her age is {element['age']}.")
# This is what is contained in my ages list
ages