Introduction to SQL¶
What are SQL and MySQL?
SQL, Structured Query Language, is a computer language that allows you to communicate with databases.
MySQL is a Relational Database Management System, RDBMS, used to interact with a database. It serves as the interface between a user and a database allowing the user to employ SQL to interact with the database.
Fundamental RDBMS Terms¶
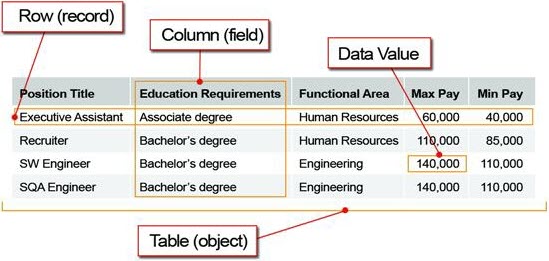
A Relational Database Management System is a collection of related tables used to store and manage data. Each table should have a primary key serving as its unique identifier.
Flavors or Dialects-> MySQL, PostgreSQL Oracle, Access, MS SQL
A schema is like a blueprint for a database showing the relationships between tables and their primary and foregin keys. In MySQL, the term is interchangeable with database.
A Table is a collection of records. Each table should have a primary key and may have a foreign key relating it to another table in the database.
A Record is a single observation or row in a table.
A Field is a single category or column in a table.
A Value is the content of a single cell.
So What Are the Data Types in MySQL?
When a database is developed using MySQL, each column must be assigned a specific data type and as an option, data length.
Data Types¶
Common Numeric Data Types
INTis a number without a decimal point.
DECIMAL(P,D)stores an exact number up to P digits with D decimals.
FLOATis a single-precision floating point number andDOUBLEis a double-precision floating point number.
UNSIGNEDan optional attribute that limits numeric data to positive values only.
Boolean Data Types
TINYINTis used to handle boolean data types in MySQL and treats0s asFalseand1s asTrue.
Common String Data Types
CHAR(length)is a fixed length, non-binary stringCHAR(5)
VARCHAR(length)is commonly used for strings without a fixed length but no more than 255 characters.
TEXTis used for strings without limits on length.
Null Data Type
NULLis the absence of a value and is treated as a0.
Date and Time Data Types
DATEis typically displayed as'YYYY-MM-DD'and does not include time data.
TIMEuses 24-hour times using'hh:mm:ss'format.
DATETIMEis a combined data and time value typically displayed as'YYYY-MM-DD HH:MM:SS'
TIMESTAMPformated in'YYYY-MM-DD HH:MM:SS'does allow for time zone consideration.
YEARcan be in'YYYY'or'YY'format.
Now What?
Using SQL queries, I can perform CRUD operations, Create, Read, Update, Delete. I'll show a basic example of what it looks like to CREATE a table to hold data, but then I'll focus mostly on queries that READ the data.
column_name data_type(length) [NOT NULL] [DEFAULT value] [AUTO_INCREMENT] column_constraint;
Example Syntax to Create a New Table
CREATE TABLE IF NOT EXISTS tasks (
task_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
start_date DATE,
due_date DATE,
status TINYINT NOT NULL,
priority TINYINT NOT NULL,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=INNODB;
Above you see that there are possible column constraints available like NOT NULL, UNIQUE, CHECK, PRIMARY KEY, and FOREIGN KEY.
This is the source of the thorough tutorial on MySQL Data Types and Table Creation with code samples referenced above.
MySQL Commands to Navigate¶
/*
Use the following commands to inspect information about available databases and tables.
*/
--View available databases for use.
SHOW DATABASES;
--Select a database for use. (database names ARE case sensitive)
USE database_name;
--Discover which database you currently have selected for use.
SELECT DATABASE();
--Discover available tables for use withing my selected database.
SHOW TABLES;
--Inspect the structure of a table. (table names ARE case sensitive)
DESCRIBE table_name;
--Observe the query used to create a table or database name.
SHOW CREATE TABLE table_name;
SELECT help_topic_id, help_category_id, url FROM mysql.help_topic
Fundamental SQL Terms¶
A Query is a request that returns information or records. A query can contain multiple clauses, each containing one or more SQL keywords, but it can also be as simple as a SELECT * statement that returns all fields followed by a FROM table_name clause indicating the table you want the data to come from.
A Statement is any valid piece of code that is executable by a RDBMS.
A Clause is a subsection of a query that contains at least one keyword and the accompanying information, like fields or tables, to be used with the keyword.
A Keyword is a reserved word that performs an operation.
Clause Written Order¶
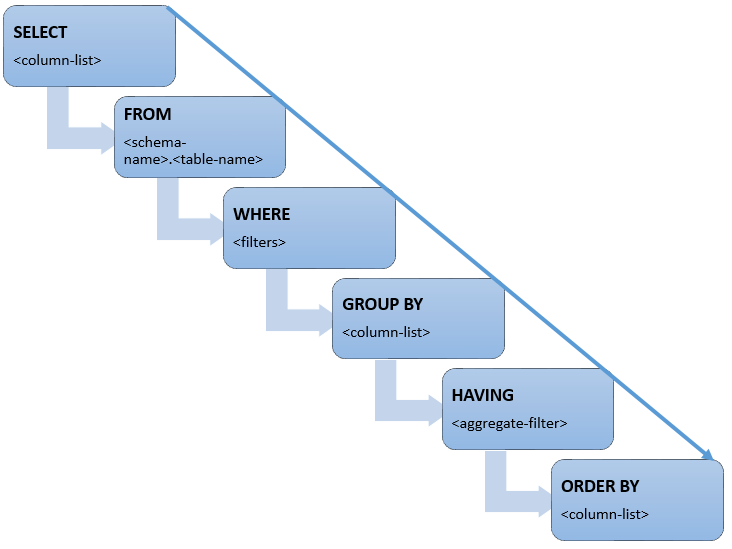
Clause Run Order¶

Query Structure¶
When creating a query, you might organize your thoughts with the following questions first:
- What database will you be using?
- What table(s) within the database will you be querying?
- Will you need to join any tables to get the information you want or filter by a specific field?
- What fields in the table are you interested in?
- Will you need to filter your data or are you interested in a specific time range?
- What will your query do, in plain English?
What Is Filtering
Filtering Keywords¶
I can narrow the result sets returned to me by my queries using filtering clauses made up of certain keywords and operators. Here I list some examples, but you will see these in action in the examples below.
Example Filtering Keywords:
WHERE,HAVING,SELECT DISTINCT
So What Are Operators?
Operators¶
Operators are keywords that are used in conjunction with other clauses; they cannot stand alone as clauses.

Now What?
Combine operators with clauses like the examples below.
WHERE Clause¶
I can add specific conditions to my queries using a WHERE clause paired with different operators to limit the resulting result set to records that satisfy my specific conditions. By using WHERE with the = sign, I am filtering for one specific value, in this case Fleetwood Mac as the artist.
--I'm using the albums_db database
USE albums_db;
--I want to see all of the fields for records by the artist Fleetwood Mac in the albums table.
SELECT *
FROM albums
WHERE artist = 'Fleetwood Mac';
DISTINCT, BETWEEN Keywords¶
I can filter for unique values in a column by using the keyword DISTINCT, and I can get the values that fall within an inclusive range by using the keyword BETWEEN.
I'm treating release_date below as a date data type; the single quotes can be dropped when it is an integer.
/*
I want to see a list of artists that released albums in the 90s; each artist only needs to be in the list one time, and I want them ordered in descending order by release_date.
*/
SELECT DISTINCT artist
FROM albums
WHERE release_date BETWEEN '1990' AND '1999'
ORDER BY release_date DESC;
IN , LIKE, % Operators¶
Here I use the IN operator to find specific values within a dataset, while using the LIKE operator with a text wildcard (%) to find variations on my input. The % symbol represents one or more of any character, so my WHERE clause is searching rows that have 'rock' somwhere in the value for the genre column.
/*
I want to see the artist name, album name with alias title, and the release date with alias date for the records where the genre has any form of the word rock in it and the release date was in the 90s; I want the records displyed from the newest to oldest release dates.
*/
SELECT artist,
name AS title,
release_date AS date
FROM albums
WHERE genre IN (genre LIKE '%rock%')
AND release_date BETWEEN '1990' AND '1999'
ORDER BY date DESC;
AND, OR Operators¶
Here I combine operators NOT and LIKE with a wildcard symbol, %, to exclude artists whose names start with the letter 'm' followed by any number of unknown letters. We can use the OR operator to find values that match any of our criteria, while using the AND operator requires that a value match all of our criteria.
--I want to see the same list as above except without records for artists whose names start with the letter m.
SELECT artist,
name AS title,
release_date AS date
FROM albums
WHERE genre IN (genre LIKE '%rock%')
AND release_date BETWEEN '1990' AND '1999'
AND artist NOT LIKE 'm%'
ORDER BY date DESC;
Grouping and Patterns¶
I can use the _ character to represent one unknown character before or after a known character. Below, I am using artist LIKE '_a%' to represent an unknown starting character followed by the letter 'a' and any number of other characters. In other words, I am looking for any artist that has the letter 'a' as the second letter in their name.
--I'm using the albums_db database
USE albums_db;
--I want to see all of the fields for records where artists have the letter 'a' as the second letter in their name or end in the letter 'd' and have a release_date before the year 1990.
SELECT *
FROM albums
WHERE (artist LIKE '_a%'
OR artist LIKE '%d')
AND release_date < '1990';
What Are SQL Functions?
A SQL Function is a sub-program used in SQL database applications for processing and manipulating data; they can be divided into aggregate and scalar functions. I will give examples of scalar types directly below and aggregate types further down in the GROUP BY section, but there are too many built-in functions to exemplify here. You can see a Full List here.
So What Are Some Common Built-in Functions?
String Functions (scalar type)¶
CONCAT()¶
The concat() function returns a single string from combined arguments.
CONCAT('first_name', ' ', 'last_name')
-> Faith Kane
SUBSTR()¶
The SUBSTR() function returns a string that is n characters long starting from the character that falls at the start position argument passed.
SUBSTR(artist, -1, 5)
-> rtist
LENGTH()¶
The LENGTH() function returns the length of the string argument.
SELECT LENGTH(last_name)
FROM employees
WHERE last_name LIKE 'a%';
-> 5
7
...
TRIM()¶
The TRIM(string) function removes both leading and trailing spaces from the string argument.
UPPER()¶
The UPPER(string) and LOWER(string) functions return the string with all characters changed to either uppercase or lowercase.
REPLACE()¶
The REPLACE(string, from_string, to_string) function is case sensitive and replaces all occurances of the from_string with the to_string.
These are just a few common string functions. There are way too many to cover here, so see the full list here.
Date and Time Functions (scalar type)¶
DATE()¶
The DATE() function extracts the date part of a date or datetime expression.
SELECT DATE('2020-07-24 01:00:03');
-> 2020-07-24
NOW()¶
The NOW() function returns the current date and time.
SELECT NOW();
-> 2020-07-24 00:59:09
CURDATE()¶
The CURDATE() function returns the date without the time.
SELECT CURDATE();
-> 2020-07-24
CURTIME()¶
The CURTIME() function returns the UTC time without the date.
SELECT CURTIME();
-> 01:00:09
UNIX_TIMESTAMP()¶
The UNIX_TIMESTAMP() argument returns the number of seconds since January 1, 1970. The %Y-%m-%D format is required by this function if you pass it a date.
SELECT UNIX_TIMESTAMP();
returns 1595552508
DATEDIFF()¶
The DATEDIFF(exp1 - exp2) returns the difference between exp1 and exp2 in days.
SELECT DATEDIFF('2020-1-30 23:59:59','2020-1-29');
-> 1
Now What?
Here's an example of nested string functions in the SELECT statement of SQL query.
SELECT first_name,
last_name,
LOWER(
CONCAT(
SUBSTR(first_name, 1, 1),
SUBSTR(last_name, 1, 4),
"_",
SUBSTR(birth_date, 6, 2),
SUBSTR(birth_date, 3, 2)
)) AS user_name
FROM employees;
Here's an example using the DATEDIFF() and CURDATE() nested as a calculated field in the SELECT statement displaying an employee's length of employment in days.
SELECT
emp_no,
birth_date,
hire_date,
last_name,
gender,
DATEDIFF(CURDATE(),
hire_date) AS days_employeed
FROM employees
WHERE birth_date LIKE '%-12-25'
AND hire_date BETWEEN '90-01-01' AND '99-12-31';
GROUP BY¶
The GROUP BY clause divides rows or records into summary rows; it does this by grouping rows with identical values in a certain field or combination of fields. Basically, if a specified column, or columns, contains duplicate values, GROUP BY will make a group of the records with those duplicate values and display them in a single row. It is used to adjust the level of detail in your result set.
If my function is going to run over multiple rows or records, I need a
GROUP BYclause.If my function is running over multiple columns in the same row or record, I don't need a
GROUP BYclause.
Aggregating Data¶
I can use the GROUP BY clause with aggregate functions to return summary statistics.
A GROUP BY clause can be combined with aggregate functions to turn a range of numbers into a single data point based on a variety of mathematical operations.
SUM(),MIN(),MAX(),COUNT(),AVG(),STDDEV()
Using the GROUP BY clause and the COUNT() function with the * column wildcard symbol to get a count of all records grouped by whether passengers have the female or male value in the gender field.
USE titanic_db;
SELECT
sex,
COUNT(*) AS passenger_count
FROM passengers
GROUP BY sex;
-> female 314
male 577
Using the GROUP BY clause with more than one field or column allows me to work with unique combinations of fields; here I look for unique first and last name combinations with a count of each unique combination. Notice that both non-aggregated fields in my SELECT statement are included in my GROUP BY clause.
USE employees;
SELECT
first_name,
last_name,
COUNT(*) AS emp_count
FROM employees
WHERE last_name LIKE 'E%E'
GROUP BY first_name, last_name
ORDER BY emp_count DESC;
-> Adib Etalle 3
Radhia Erie 2
...
Using the GROUP BY clause with the LIKE and NOT LIKE operators to filter the last_name field and getting a count of records in my result set using the COUNT() function.
SELECT
last_name,
COUNT(*) AS emp_count
FROM employees
WHERE last_name LIKE '%q%'
AND last_name NOT LIKE '%qu%'
GROUP BY last_name
ORDER BY emp_count;
-> Qiwen 168
Chleq 189
Lindqvist 190
Using the GROUP BY clause with a subquery and a WHERE filter to get both a total and count of records in my subquery result set using both the SUM() and COUNT() functions. The WHERE clause is used for filtering non-aggregated data, so I'm using it outside of my subquery that's using a GROUP BY clause.
SELECT
SUM(names.num) as dup_user_names,
COUNT(names.num) as unique_dup_user_names
FROM
(SELECT LOWER(
CONCAT(
SUBSTR(first_name, 1, 1),
SUBSTR(last_name, 1, 4),
"_",
SUBSTR(birth_date, 6, 2),
SUBSTR(birth_date, 3, 2)
)) AS user_name,
COUNT(*) AS num
FROM employees
GROUP BY user_name
ORDER BY num DESC) AS names
WHERE num > 1;
-> dup_user_names unique_dup_user_names
27403 13251
Using the GROUP BY clause with a subquery and HAVING filter to get both a total and count of records in my subquery result set using both the SUM() and COUNT() functions. HAVING is used for filtering results with aggregates, so I can use it inside of my subquery that's performing a GROUP BY to aggregate.
SELECT SUM(names.num) as dup_user_names,
COUNT(names.num) as unique_dup_user_names
FROM
(SELECT LOWER(
CONCAT(
SUBSTR(first_name, 1, 1),
SUBSTR(last_name, 1, 4),
"_",
SUBSTR(birth_date, 6, 2),
SUBSTR(birth_date, 3, 2)
)) AS user_name,
COUNT(*) AS num
FROM employees
GROUP BY user_name
HAVING num > 1
ORDER BY num DESC) AS names;
-> dup_user_names unique_dup_user_names
27403 13251