SQL Tables and Joins¶
What Makes Tables in a Database Relational?
Often times you will need to combine the information from two or more tables to answer your query. We need to understand the different ways tables relate to each other and how to join them to get at the data we want.
Table Keys¶
A Primary Key is the unique identifier for a record in a table. You cannot have a Null value in the primary key column, nor can any two records share the same value in this field. There can only be one primary key for a table, and it is common to add the AUTO_INCREMENT attribute to your primary key column, which by default starts counting forward from 1 and generates a unique identity for any new rows added to a table.
A Foreign Key is a field in a table that serves as the primary key for another table. Although this field must contain unique values in the table for which it serves as a primary key, it does NOT have to contain unique values in the table for which it serves as a foreign key. Unlike the primary key, you can have more than one foreign key in a single table; a table that contains multiple foreign keys to relate other tables to each other is known as an associative table. More on these below.

- A composite key is when a table has a primary key that's actually a unique combination of more than one column; it's a multiple-column index. The primary key is comprised of a unique combination of two or more fields and serves as the unique identifier for each record.

Table Relationships¶
A One-to-One Relationship is when each row in one table has only one related row in a second table.
A One-to-Many Relationship is when one record in a table can be associated with one or more records in another table.
For Example: In the CUSTOMERS table above, the CustomerNo field is the primary key and must be unique (ONE). Each customer has a unique code in the CUSTOMERS table but that code can be used multiple times (MANY) in the ORDERS table with the uniqe id OrderNo, the primary key in the ORDERS table. The foreign key field in the ORDERS table, CustomerNo, can appear multiple times because a single customer from the CUSTOMERS table can have multiple orders, each with a unique OrderNo.
- CustomerNo may appear only ONE time in the CUSTOMERS table but MANY times in its related ORDERS table. One-to-Many
A Many-to-Many Relationship is when multiple records in one table are associated with multiple records in another table. To make this type of relationship work, we need a associative or joiner (also known as junction) table that holds the primary keys of the two or more tables that have many-to-many relationships.
For Example: Say we had a table called Students that had a primary key called StudentID representing a student at UTSA and a table called Classes that had a primary key called ClassID representing the different classes offered in a given semester.
| StudentID | StudentName |
|---|---|
| 1 | John |
| 2 | Faith |
| ClassID | ClassName |
|---|---|
| 1 | math |
| 3 | science |
| 4 | art |
| 5 | yoga |
| 9 | fencing |
The StudentID would have to be a unique identifier for each record in the Students table, but one student is most likely taking more than one class a semester. One student can take multiple classes, but each class will also have more than one student enrolled for the semester. This is a many-to-many relationship, so if we tried to put StudentID in the same table as ClassID, we would have multiple values in a single field. This is not ideal!
| StudentID | ClassID | StudentName |
|---|---|---|
| 1 | 3, 5, 9 | John |
| 2 | 1, 4, 5, 9 | Faith |
An Associative or Joiner Table maps two or more tables together by referencing the primary keys of each table. A joiner table can be thought of as a base table that resolves many-to-many relationships; it contains the primary keys for each table it cross references or joins.
For Example: We could have a joiner table called Enrollment, like you see below, that holds and connects the primary keys for both the Students and Classes tables.
| StudentID | ClassID |
|---|---|
| 1 | 3 |
| 1 | 5 |
| 1 | 9 |
| 2 | 1 |
| 2 | 4 |
| 2 | 5 |
| 2 | 9 |
Let's check out how to join the information in these different kinds of tables.
So What Kinds of Joins Exist?
Joins are commands that combine the fields from two or more tables in a relational database using shared primary and foreign key columns. There are several different kinds of joins to choose from depending on what data you want to include or exclude.
Quick Reference for Joins¶
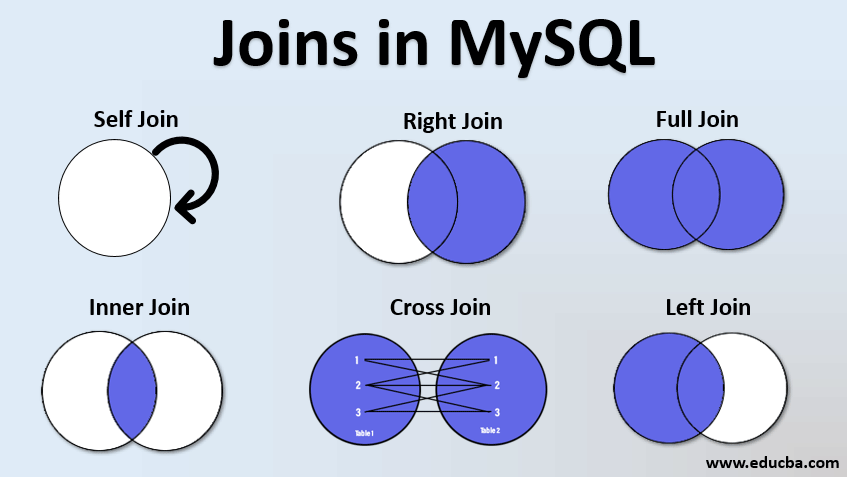
Now What?
JOIN Examples¶
Let's check out some code examples. These can serve as useful syntax references when you try to write a query down the road and haven't seen SQL in a few weeks!
-- Query SELECTS all from simple joining of employees and salaries tables.
SELECT *
FROM employees
JOIN salaries USING(emp_no);
-- Query joins three tables, filters with a WHERE clause, and uses an ORDER BY clause.
SELECT d.dept_name AS 'Department Name',
CONCAT(e.first_name, ' ', e.last_name) AS 'Department Manager'
FROM employees AS e
JOIN dept_manager AS dm ON e.emp_no = dm.emp_no
AND to_date > CURDATE()
JOIN departments AS d ON dm.dept_no = d.dept_no
WHERE e.gender = 'F'
ORDER BY d.dept_name;
-- Query uses a GROUP BY cluase with an aggregate function and filters tables in the JOIN clauses.
SELECT t.title AS Title,
COUNT(t.title) AS Count
FROM titles AS t
JOIN dept_emp AS de ON de.emp_no = t.emp_no
AND de.to_date > CURDATE()
AND t.to_date > CURDATE()
JOIN departments AS d ON d.dept_no = de.dept_no
AND d.dept_name = 'Customer Service'
GROUP BY t.title;
/*
Query uses a GROUP BY clause with an aggregate function nested in a ROUND() function to round average salary to two decimal places, filters tables in JOIN clauses, uses an ORDER BY clause to sort average salary in descending order, and uses a LIMIT clause to return only the first record of the result set.
*/
SELECT d.dept_name,
ROUND(AVG(s.salary),2) AS average_salary
FROM departments AS d
JOIN dept_emp AS de ON de.dept_no = d.dept_no
AND de.to_date > CURDATE()
JOIN salaries AS s ON s.emp_no = de.emp_no
AND s.to_date > CURDATE()
GROUP BY d.dept_name
ORDER BY average_salary DESC
LIMIT 1;
--Query chains AND clauses to filter in a JOIN clause.
SELECT e.first_name, e.last_name
FROM departments AS d
JOIN dept_emp AS de ON de.dept_no = d.dept_no
AND de.to_date > CURDATE()
AND d.dept_name = 'Marketing'
JOIN salaries AS s ON s.emp_no = de.emp_no
AND s.to_date > CURDATE()
JOIN employees AS e ON e.emp_no = s.emp_no
ORDER BY s.salary DESC
LIMIT 1;
Here I do a self join referencing employees a second time in my query but this time aliased managers. Self Joins require you to use table aliases in order to reference a table twice or more in a query. I join it using the employees table's emp_no or primary key column that it shares with the dept_manager table. I want to access the names of the current managers in my query, so I also filter the to_date field on each table that contains that column.
-- Find the names of all current employees, their department names, and their current managers' names using a self join.
SELECT CONCAT(e.first_name, ' ', e.last_name) AS 'Employee Name',
d.dept_name AS 'Department Name',
CONCAT(managers.first_name, ' ', managers.last_name) AS 'Manager_name'
FROM dept_emp AS de
JOIN employees AS e USING(emp_no)
JOIN departments AS d ON d.dept_no = de.dept_no
JOIN dept_manager AS dm ON dm.dept_no = d.dept_no
AND dm.to_date > CURDATE()
JOIN employees AS managers ON managers.emp_no = dm.emp_no
WHERE de.to_date > CURDATE()
ORDER BY d.dept_name;
What Is a Subquery?
A subquery is when one query is nested inside of another; they are most commonly used in SELECT, FROM, and WHERE clauses but can also be used in a JOIN clause. When a subquery is in your FROM clause, it is called a derived table, and it MUST be given a table alias.
So What Are They Used For?
Using a subquery allows us to use a query result set from one table when querying another table without using a JOIN. Here we are using WHERE with IN in a subquery. This type of subquery is fast, but the rub is that we don't have all of the columns available in the inner query. Its usefulness depends on your data needs.
Now What?
Subquery Examples¶
Let's check out some code examples. These can serve as useful syntax references when you try to write a query down the road and haven't seen SQL in a few weeks!
Here is an example of using two subqueries in the WHERE clause with the operator AND.
SELECT first_name, last_name
FROM employees
WHERE emp_no IN (
SELECT emp_no
FROM salaries
WHERE salary BETWEEN 60000 AND 70000
AND to_date > CURDATE()
)
AND emp_no IN (
SELECT emp_no
FROM dept_manager
);
Here is an example of a derived table, which is simply a subquery in your FROM clause. Notice, this derived table has the alias 'sal'; remember that aliases are a must for derived tables, or an error will occur.
SELECT sal.emp_no,
salary
FROM (
select salary, emp_no
from salaries
where salary between 60000 and 70000
) as sal
JOIN dept_emp USING(emp_no)
JOIN departments USING(dept_no);
However, you can also use a subquery in a JOIN clause. Here, we are selecting from a derived table. This method can be computationally expensive, but it gifts you with added flexibility.
SELECT e.first_name,
e.last_name,
monies.salary
FROM employees AS e
JOIN (
SELECT salary, emp_no
FROM salaries
WHERE salary BETWEEN 60000 AND 70000
AND to_date > CURDATE()
) AS monies USING(emp_no);
Here, I'm using a subquery instead of a self join to get the same result set as in the self join example above.
-- Find the names of all current employees, their department names, and their current managers' names using a self join.
SELECT CONCAT(e.first_name, ' ', e.last_name) AS 'Employee Name',
d.dept_name AS 'Department Name',
b.dept_manager AS 'Manager Name'
FROM employees AS e
JOIN dept_emp AS de ON de.emp_no = e.emp_no
AND de.to_date > CURDATE()
JOIN departments AS d USING(dept_no)
JOIN (
SELECT dm.dept_no,
CONCAT(e.first_name, ' ', e.last_name) AS dept_manager
FROM employees AS e
JOIN dept_manager AS dm ON dm.emp_no = e.emp_no
AND dm.to_date > CURDATE()
) AS b USING(dept_no)
ORDER BY d.dept_name;
I can also return the result of a mathematical calculation using subqueries.
-- Find the percent of employees whose salaries are within one standard deviation of the highest salary.
SELECT
(SELECT
COUNT(salary)
FROM salaries
WHERE to_date > CURDATE()
AND salary >= (
SELECT
MAX(salary) - STDDEV(salary)
FROM salaries
WHERE to_date > CURDATE()
))
/
(SELECT
COUNT(salary)
FROM salaries
WHERE to_date > CURDATE()) * 100 AS percent_of_salaries;